
Domain Adaptation
[computer-vision Machine learning performance depends on the dataset that it is trained on. Datasets are imperfect, so problems in the data affect the models. One type of problem is domain shift. This means that a model trained to learn a task on one dataset, may not be able to perform the same task on a slightly different dataset.
Say you train a model to detect dogs in outdoor settings like public parks. It may perform very well on test images of dogs in outdoor places. However, that model may not function well when trying to detect dogs indoors, although the task itself is identical. This is a problem because the background of the image should not matter since you are just trying to detect dogs. We will explore four different research papers that address this problem.
Vocabulary
There are two datasets: a source dataset and a target dataset. The dataset that the model is trained on is the source dataset. The target dataset is the one that it will be tested on.
For domain generalization, a similar problem, the target dataset is not available during training. The network is trained on the source dataset to not overfit to the domain-specific features.
In domain adaptation, both the source and target datasets are available during training, but labels for the target dataset are not always available. For unsupervised domain adaptation, there are no labels available for the target dataset during training time. Semi-supervised domain adaptation involves a few labeled examples from the target dataset. With supervised domain adaptation, all the data from both the source and target datasets have labels.
Unsupervised domain adaptation is the most commonly studied problem, as it has the most applications. Supervised DA can be useful when you have a labeled dataset, but it is too small to directly train on.
These methods can be applied to many ML problems. However, a common application is image classification. I will focus on image classification on two common benchmark datasets: MNIST and SVHN. A model trained on handwritten digits (MNIST) often performs poorly on printed house number digits (SVHN).
Adversarial Methods
The most common approaches to the domain adaptation method follow an adversarial approach. For some context, I would suggest reading about Generative Adversarial Networks (GANs).
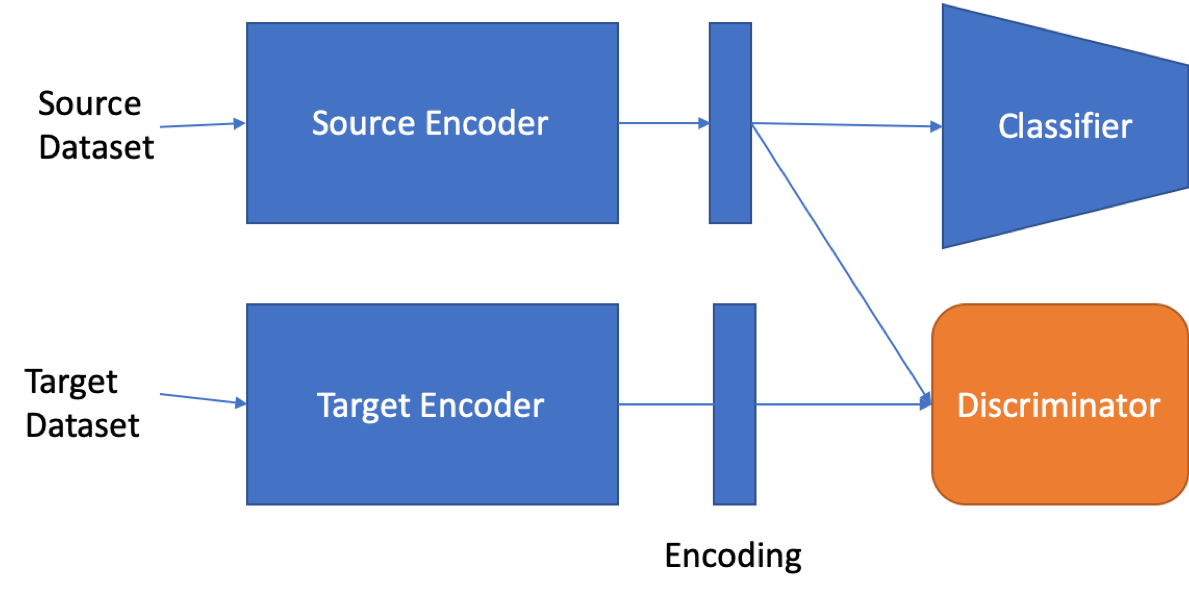
There are two encoders, which learn to produce a vector representation of each input. There is a classifier to classify the inputs and a discriminator that is trained to differentiate between the datasets. The goal is to eliminate differences in the domain from the encodings. This is similar to the GAN objective in that we want the encoders to fool the discriminator by generating encodings that are difficult to differentiate. However, this needs to be done such that the classifier is also effective for both datasets. The same classifier can then be applied to both datasets.
There are many approaches to this with different training methods, architectures, and losses. The high-level goal is consistent. We want the encoders to generate encodings that contain the useful information needed for classification but remove the shift in domains. The key difference between the many algorithms is what the discriminator is and how it is trained. In simple cases, it is just an additional loss term. For example, maximum mean discrepancy (MMD) measures the difference between the encodings of the source and target datasets. Training the networks while minimizing the discrepancy can reduce domain shift. This may be useful for simple DA problems but does not work well for larger disparities.
ADDA
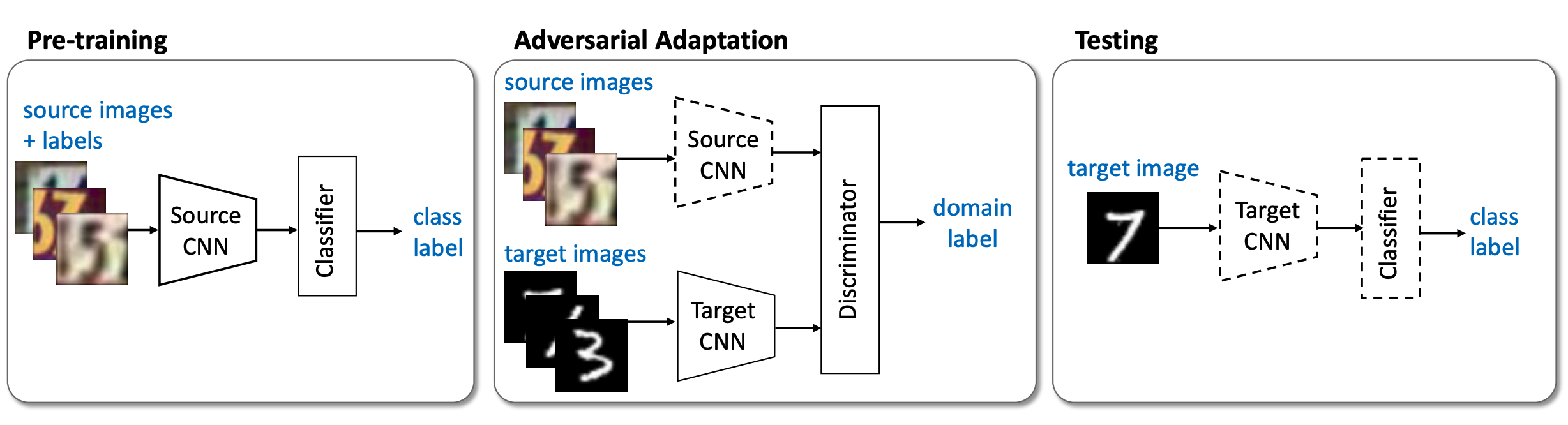
Adversarial Discriminative Domain Adaptation (ADDA) applies a simple approach to discriminative DA. There is only one encoder shared between the source and target datasets. The networks are trained in two steps.
-
The encoder and classifier are first trained to achieve high classification accuracy on the source dataset.
-
The encoder is trained with the discriminator to lose domain discriminability. The discriminator is trained to classify the two domains with an adversarial loss. The encoder is trained with the negation of this loss since it is adversarial with respect to the discriminator. This negative is done through gradient reversal, which means in backpropagation, the gradients are negated before going to the encoder.
One major shortcoming of this approach is that the classification performance can be lost or forgotten in the adaptation step. This is because the labels are not used in this step.
DANN

Domain-Adversarial Training of Neural Networks (DANN) is very similar to ADDA. Rather than have a separate adaptation step, the domain discriminator is trained alongside the classier. A gradient reversal layer is used because the domain discriminator and the classier have adversarial loss functions. This allows classification and discrimination to be trained together and avoid the network from forgetting the task.
Image Translation
Another approach to addressing the domain gap is to convert examples from one domain to another. An example of this is transforming street-view digits (SVHN) to look like handwritten MNIST (digits). After this translation, you can apply an MNIST trained image classifier. The architectures are more complex because, in addition to the main task (image classification), the networks must translate images to and from the source and target domains.
![]()
Image to Image translation

Like the adversarial methods Image to Image Translation (I2I) aims to learn a domain invariant encoding (Z) for the images. There are six networks in this architecture: the source encoder, source decoder, target encoder, target decoder, domain discriminator, and task network (ex: classifier). The decoders aim to reconstruct the images from the encoding. This also includes adversarial learning with the domain discriminator.
The network is trained on a weighted combination of six different losses. The paper studies which combination of losses yields the best performance.
-
Qc is the classification loss on the source domain. We cannot get this loss for the target domain since there are no labels. However, the loss can be extended to include the target domain if labels exist.
-
Qid is the loss of encoding an image and decoding it back into the same domain. Encoding an image into Z and decoding it back to the original domain should ideally return the same image. This loss can be the L1 norm of the difference between the original and decoded image.
-
Qz is the domain discriminator’s loss. This is similar to ADDA in that it is trying to determine the domain of the encoding. We want this loss to increase as the encodings improve.
-
Qtr is another discrimination loss in which the image is translated into the other domain before going to the domain discriminator.
-
Qcyc is the cycle consistency loss. This loss is similar to Qid. The difference is that the images are decoded in the other domain before being encoding and decoded in the original domain. The image from the source domain is encoded into Z. This is decoded into the target domain and encoded back to Z. This is then decoded into the source domain and compared with the original image. A loss with the source and target switched is also applied. This aims to ensure encodings from similar images in different domains have similar encodings.
-
Qtrc is similar to Qcyc, but instead of decoding back into the original domain, the encoding is classified. Unlike Qcyc, this is not symmetric since it involves labels. An image from the source domain is translated into the target domain and then classified.
CyCADA

CyCADA is similar to I2I. Many of the I2I losses and networks have counterparts here. The main difference is that the target images are not translated to the source domain. Also, the GAN losses can be applied to both the images and the encodings.
The source images are translated into the target domain. They are translated back into the source domain to apply the cycle consistency loss (L1 difference with the original image).
The fs network is trained on the supervised learning task in the source domain. The semantic consistency loss ensures that the features from this network remain close before and after translation into the target domain. This ensures that the images retain the semantic information after translation.
A GAN loss is then applied to the images and features (from fT) for the translated images and the target images. This loss is needed to train the translations to be similar to the target domain. There are two GAN losses to ensure that both the images and the features are similar.
Finally, a task loss is applied to the translated images. This applies the task to the original target images.
Other Domains
Image classification is the primary problem used to benchmark domain adaptation methods. However, domain adaptation can also be applied to other computer vision problems, such as image segmentation. It can also be applied in different research areas, such as natural language processing (NLP).
One particularly interesting application of domain adaptation is self-driving cars and robotics. It is a common practice to train deep neural networks for these applications using data from simulated environments. It is much easier to collect large amounts of data in a simulation rather than in the real world. However, in order for a model trained on simulation data to function in a real-world environment, domain adaptation is often required to achieve good performance.
There are also many variants to the problem, including few-shot domain adaptation, domain generalization, and multiclass domain adaptation.
Conclusion
There are several approaches to domain adaptation but they often share some common characteristics. Adversarial learning with a domain discrimination network is common. There is also a lot of work using image to image translation with a cycle consistency loss. Apply domain adaptation to new problems will likely involve some combination of these components.
References
[1] Long, Mingsheng, et al. “Learning transferable features with deep adaptation networks.” International conference on machine learning. PMLR, 2015.
[2] Eric Tzeng et al. “Adversarial discriminative domain adaptation”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 7167-7176.
[3] Yaroslav Ganin and Victor Lempitsky. “Unsupervised domain adaptation by backpropagation”. In: arXiv preprint arXiv:1409.7495 (2014).
[4] Zak Murez et al. “Image to image translation for domain adaptation”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 4500-4509.
[5] Hoffman, Judy, et al. “Cycada: Cycle-consistent adversarial domain adaptation”. In: arXiv preprint arXiv:1711.03213 (2017).